Backed by

Run and use off-cloud AI on infrastructure you control
Run, scale and manage the latest AI models on your own hardware and infrastructure.


Where the work happens. One interface to everything running through Loc.ai: query your databases, transcribe and search audio, develop documents.
There is no ‘no-AI’ option — only governed AI you can see, or shadow AI you can’t.
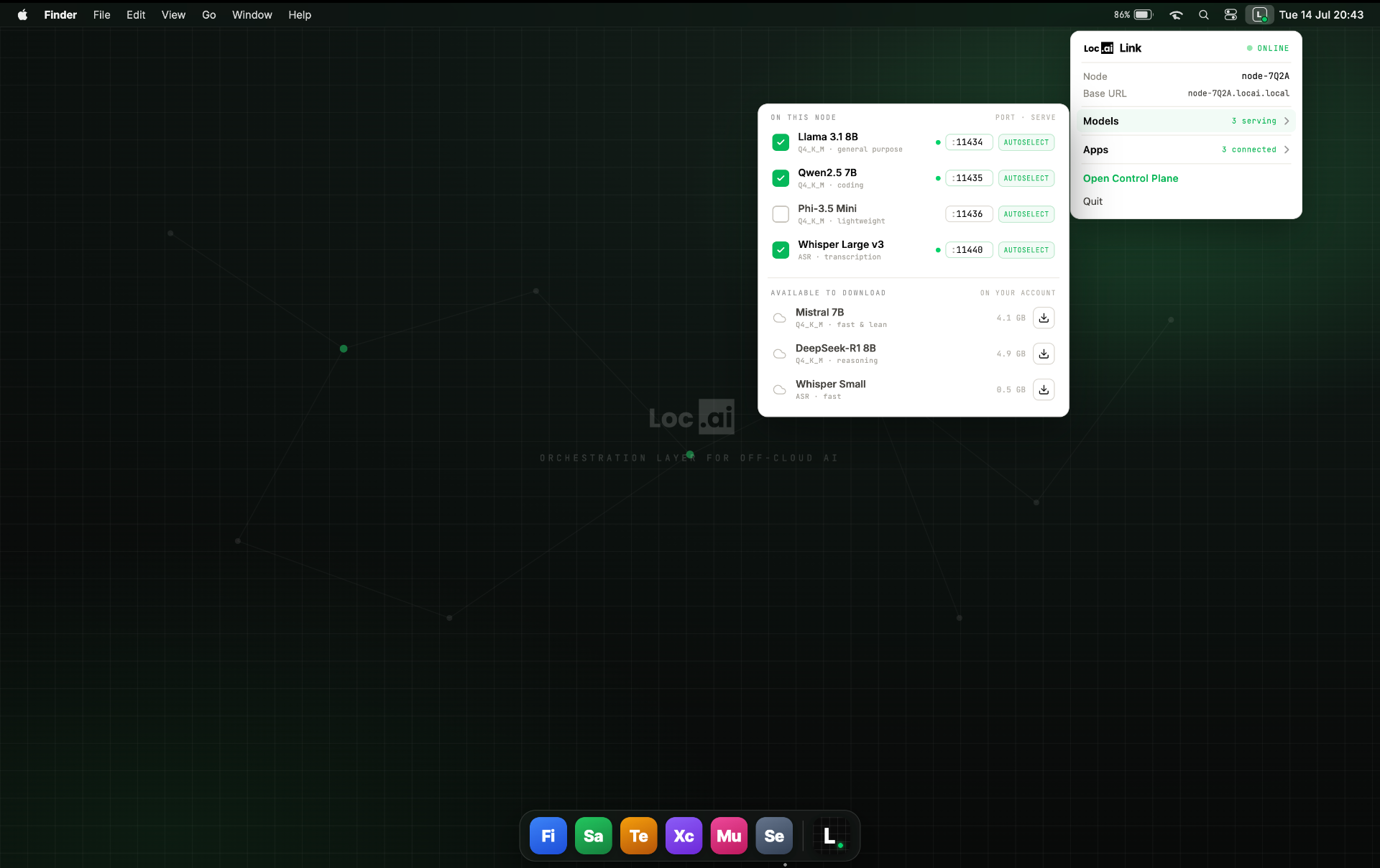
Every kind of model, with the data tied together
Most private AI tools run language models and stop. Locai runs the full range on one control plane: chat and agents, meeting and call transcription, video analysis, and object detection for visual inspection. All on your hardware, on-premise or air-gapped.
Language models
Chat, summarisation, extraction, and in-domain agents on your own hardware.
Audio transcription
Transcribe meetings, calls, and recordings on-site.
Video processing
Analyse video locally. No footage leaves your environment.
Image processing
Object detection and visual inspection for QA workflows, on-device.
Your models' data works together
Because every model runs on one platform, output from one flows into the next. On-site cameras detect a defect. The image model logs it. The document model compiles the QA report. No data leaves your environment, and no integration glue between point tools.
Running in your environment in under an hour
- 01
Install Control on your servers with one command.
- 02
Deploy models from the registry, or bring your own. GGUF, ONNX, and TFLite supported.
- 03
Point your existing stack at Locai's OpenAI-compatible endpoint. No code changes.
Hardware agnostic. NVIDIA, AMD, Apple silicon, and CPU-only nodes on one estate.
Full architecture and docsHow we stack up
FAQ
Building an AI product? Locai routes inference to your users' own devices, cutting your inference bill 60%+. See Locai for SaaS